Findings #3

Hello again. This one is coming a day later than usual as I took a little time to unwind over the long weekend. I hope you all had some time to relax as well.
This week I was sent some interesting news on a new AI system that has achieved CE mark. The product by Oxipit is focused on fully automated reporting for chest X-Rays. In particular, if it has strong confidence the scan is normal, it will create a report.
 Nicole Wetsman
Nicole Wetsman
The product received CE mark as a Class IIb product which is one of the highest I have seen to date for radiology AI. I haven't had a chance to look into the indications for use for the product but it raises a number of questions.
With any AI tool in healthcare we weigh up the chance of mistakes. In many cases we're happier to stomach some false positives if it means a lower chance of missing something critical like cancer. In the case of this new product these fully automated reports position the product to claim it will not miss anything of value.
There are a couple of ways that can be true.
The first is that the product has a really good negative predictive value (NPV). It might, I haven't tested it, but it would need a fairly sizable study to prove that is the case. The company is looking at a 2023 release in the clinical environment so time will tell. (For what it's worth, I hope it does work but I am not going to make a call until there is data). The one paper I read which seemed fairly independent showed the company's product performing fairly well but doesn't comment directly on NPV.
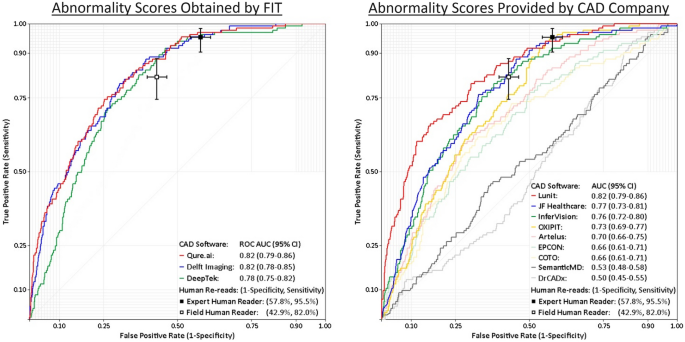
Importantly, this data needs to be robust and accurate. Lauren Oakden-Rayner a big advocate for AI safety in medicine published a paper outlining where this can go wrong. Models with great published performance metrics find themselves producing simple errors in new clinical settings due to changes in priors and underlying data. It's an interesting read and makes some practical suggestions on what to do to ensure AI works well in the clinic.

The other way this tool can succeed on paper is to have a very conservative cut off. In that case the model will be tuned to call things normal less often so as to minimise the chance of a false negative. Looking at the roll out plan in the press release there is discussion of an initial retrospective run at clinical sites. I would assume this is to give the clinical team some ability to set their own thresholds, absolving at least some of the risk.
Time will tell how this plays out but it is an interesting progression. As stated in the Verge article, CE and FDA apply different standards to evaluation and it will be interesting to see where the product lands in the US regulatory system. I wish the team all the best as they are 100% correct in saying the world needs more radiology capacity than we have today.
From Me
No essay last week due to some scheduling issues and the holidays but Tom and I did put out the latest edition of our new podcast. Check that out below if you're interested.


If you found this interesting, consider subscribing to stay up to date and forward this on to a friend.